
イラストに続き、ついに動画もAIが作ってくれる時代になりそうです。
chatGPTで知られるOpenAI 社は2月15日、打ち込んだ文章をもとにリアルな動画を制作してくれるAI「Sora」を発表しました。
文章をもとにイラストを生成するAIが社会で広く話題を呼びましたが、文章から美麗な動画を作成してくれるAIが普及すれば、YouTubeなどの動画についても、特別な知識や技術なしにハイクオリティの作品を簡単に制作できるようになるかもしれません。
今回は命令文からどんな動画が作られるかを紹介しつつ、Soraにかんする基本的な仕組みを解説したいと思います。
目次
- 動画もAIに作らせる時代がきた
- Soraの根底にある技術
- 画像生成AIが指を描くのが苦手なようにSoraにも苦手分野がある
動画もAIに作らせる時代がきた

「未来の映画監督はAIかもしれない」というのは、もはや空想の話ではないかもしれません。
OpenAIが2月15日(米国時間)発表した「Sora」は、まるで魔法のようにテキストから動画を生み出すAIモデルです。
OpenAIと言えば、会話型AIのChatGPTや画像生成ツールのDall-Eでその名を馳せていますが、動画を生成するAIツールとしては、Soraがその初陣を飾ります。
Soraの魔法は、ただの動画を超えたもの。最大60秒の長さで、細部までこだわり抜かれたシーン、カメラワークの鮮やかな動き、感情豊かなキャラクターたちを生み出します。これまでの動画生成AIがせいぜい数秒のクリップに留まっていたことを考えると、動画の長さはもちろん、その質においてもSoraはこれまでのAIを圧倒しています。
さらにSoraは、ただ複雑なシーンを生成するだけではありません。
複数のキャラクター、特定のモーション、そして対象物や背景の細かなディテールまで、ユーザーが提示した命令書を分析し、それらが現実世界でどのように存在するかまで把握できるのです。
OpenAIのSoraは、私たちが動画に求めるクリエイティビティの枠を大きく広げ、AIの可能性を新たに提示しています。
Soraのデモンストレーションを見ると、これまでの自動生成動画にはないリアリティと映像美が感じられます。
以下に、実際の命令文と、それに対してSoraが出力した動画を紹介していきます。
文章から作られた動画のデキをみてみよう
Introducing Sora, our text-to-video model.
Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions. https://t.co/7j2JN27M3W
Prompt: “Beautiful, snowy… pic.twitter.com/ruTEWn87vf
—OpenAI (@OpenAI) February 15, 2024
以下では動画作成のために入力されたプロンプト(命令文)と実際に作成された動画をいくつか紹介します。
命令書①
美しい雪の東京の街は賑わっています。カメラはにぎやかな街路を移動し、美しい雪の天気を楽しんだり、近くの屋台で買い物をしたりする数人の人々を追っています。華やかな桜の花びらが雪の結晶とともに風に乗って飛んでいきます。

命令書②
数頭の巨大な毛むくじゃらのマンモスが雪の草原を踏みしめながら近づいてくる。雪に覆われた木々、遠くに見えるドラマチックな雪を頂いた山々、うっすらとした雲と遠く高い位置にある太陽が暖かな輝きを放つ昼下がりの光、そして 低いカメラアングルからの眺めは、美しい写真と被写界深度で毛皮をまとった大きな哺乳類を見事に捉えている。

命令文③
アニメーションのシーンは、溶けた赤いろうそくのそばにひざまずく背の低いふわふわしたモンスターのアップが特徴です。画風は3Dでリアル、照明とテクスチャーに重点を置いている。モンスターは大きな目と口を開けて炎を見つめている。そのポーズと表情からは、無邪気さと遊び心が感じられる、そのポーズと表情は、まるで初めて周囲の世界を探検しているかのような、無邪気で遊び心のある感覚を伝えている。暖色系の色使いとドラマチックな照明が、画像の居心地のよい雰囲気をさらに高めている。

命令書④
温かく光るネオンとアニメーションの街の看板で埋め尽くされた東京の通りを、スタイリッシュな女性が歩いている。彼女は黒い革のジャケット、赤いロングドレス、黒いブーツを身に着け、黒い財布を持っている。彼女はサングラスをかけ、赤い口紅を塗っている。彼女は自信に満ち、さりげなく歩いている。通りは湿っていて反射し、カラフルなライトのミラー効果を作り出している。多くの歩行者が歩いている。

作成された動画はどれも命令文の内容を忠実に再現しており、まるで人間の監督や演出家の力添えがあるかのような、ドラマチックでエモい風景を映し出してくれました。
特に命令書③で作られた動画は、命令文をどんどん追加して先を作成していけば、大手映画制作会社の新作のような雰囲気を醸し出せるかもしれません。
また命令書④で作成された動画も、出演者ゼロでも映画に近い映像を作り出せる可能性を感じさせます。
これまで高いクオリティーの動画を作り出すためには多くの時間や資材が必要でしたが、これからは必要な動画資料は自分で作れる時代が来るかもしれません。
Soraの根底にある技術

この技術の裏には、2つの先進的なAI技術の融合があります。
まず、絵を描く魔法のように機能する「拡散モデル」(ランダムな画像ピクセルを徐々に具体的な画像へと変化させる技術)。
この技術は、まるでキャンバスに散らばった絵の具が徐々に形を成していくかのように、無秩序にばらまかれた画像のピクセルを、意味のある一枚の画像へと変化させることを可能にします。
これは、画像生成ツールDALL-Eが使用するのと同じ技術です。
次に、「トランスフォーマー アーキテクチャ」(連続データを文脈化してつなぎ合わせる技術)。
この技術は、情報の海を航海する船長のように、データの流れを見極め、それらを文脈に合わせて組み立てていきます。
chatGPTをはじめとした言語を扱うAIモデルでは、この技術を使って単語を繋ぎ合わせ、私たちが理解できる文章を作り出します。
動画生成AIであるSoraでは、このトランスフォーマー アーキテクチャが、ビデオクリップを視覚的な「時空のパッチワーク」として扱い、それらを巧みにつなぎ合わせて、目を見張るような映像を生み出します。
NVIDIA の上級研究者であるジム ファン氏は、ソーシャル メディア プラットフォーム X で、Sora が世界をシミュレートできる「データ駆動型の物理エンジン」であると賞賛しました。
「データ駆動型の物理エンジン」というのは、実際の世界の物理法則を基にしたシミュレーションを行うソフトウェアの一種です。
従来の物理エンジンが数学的な公式や理論に基づいて設計されているのに対し、データ駆動型は大量のデータから学習しています。
このアプローチでは、実世界で観測された現象のデータを収集し、それらのデータをもとにして、物理現象をより正確に再現できるようにします。
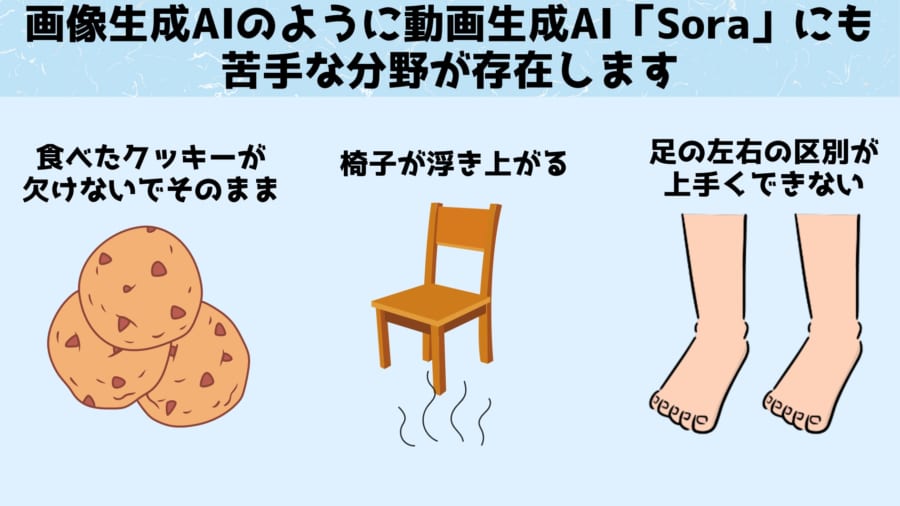
画像生成AIが指を描くのが苦手なようにSoraにも苦手分野がある
OpenAIが開発したSoraは、まるで映画のワンシーンのようなリアルな動画を作り出すことができますが、その能力の背後には、まだ乗り越えるべき課題も存在します。
複雑な動きの物理的挙動を正確にシミュレーションできなかったり、原因と結果を理解できないことがあるのです。
例えば、人がクッキーをかじった後、その跡がクッキーに反映されない場合などが確認されています。
ほかにも、歩いている人間の左右の足の位置が入れ替わったり、椅子が空中にランダムに浮かんだりと、空間に関する説明や、カメラの動きをたどるといった経時的な変化の説明を、誤って解釈することがあるようです。
同社は現行のモデルには不得意とする要素があることも認めています。
画像生成AIが人物の指の数や足の数、耳の形状を生成するのが苦手なように、Soraにも苦手分野が存在するわけです。
これらの問題を解決すべく、同社はSoraがビジュアルアーティストやデザイナー、映像製作者に公開してフィードバックを受ける予定だと述べています。
しかしそうやってより完璧な動画を作れるようになると、他のAIと同じ問題が深刻化します。
発達したAI技術によって、偽物と本物の区別が困難になる時代がますます近づいています。
たとえばSoraを音声生成AIと組み合わせると、人々が実際に行ったことのない発言や行動のディープフェイクを作成できてしまいます。
このような高度なフェイク動画は、一般人を簡単にだますことができるでしょう。
現在Soraを安全に利用できるようにするため、OpenAI社はいくつかの重要な安全対策を講じているとのこと。
特にAIがもたらす害やリスクを評価するために編成された「レッドチーム」はその中心となる存在です。
彼らは「誤った情報、憎悪に満ちたコンテンツ、偏見などの分野の専門家」として知られています。
彼らの働きが成功すれば、アイドルの熱愛、政治家の不正などの偽動画、さらには不倫の証拠をでっち上げるなどプライバシーの侵害や社会的な損失を及ぼすような偽動画の生成をブロックできるようになるでしょう。
参考文献
Introducing Sora, our text-to-video model.
https://twitter.com/OpenAI/status/1758192964222988506
ライター
川勝康弘: ナゾロジー副編集長。
大学で研究生活を送ること10年と少し。
小説家としての活動履歴あり。
専門は生物学ですが、量子力学・社会学・医学・薬学なども担当します。
日々の記事作成は可能な限り、一次資料たる論文を元にするよう心がけています。
夢は最新科学をまとめて小学生用に本にすること。
編集者
海沼 賢: 以前はKAIN名義で記事投稿をしていましたが、現在はナゾロジーのディレクションを担当。大学では電気電子工学、大学院では知識科学を専攻。科学進歩と共に分断されがちな分野間交流の場、一般の人々が科学知識とふれあう場の創出を目指しています。
